The 20th international conference on Knowledge, Information and Creativity Support Systems (KICSS2025) において、本研究室から 学生4名が研究発表 を行いました。
そして、Outstanding Paper Award & Best Poster Awardを受賞しました。
- Takano, T. Hayama, H. Cui, “Predicting Image Diffusion in Social Networks via Visual Interest Similarity,” in Proc. 20th International Conference on Knowledge, Information and Creativity Support Systems (KICSS 2025) ,pp.222-233 (2025).
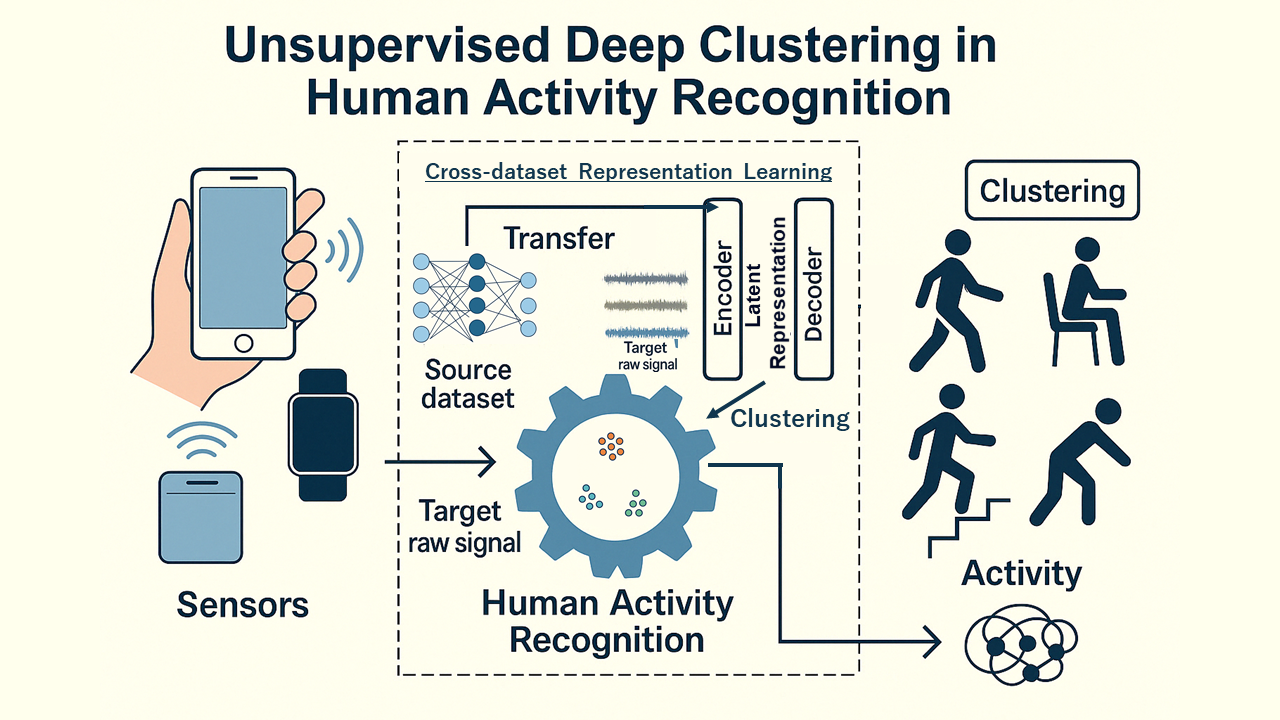
- Jia, H. Cui, T. Hayama, “HAR-DCWGAN: Dual-Conditional Wasserstein GAN for Human Activity Recognition Data Synthesis,” in Proc. 20th International Conference on Knowledge, Information and Creativity Support Systems (KICSS 2025),pp.234-242 (2025).[Outstanding Paper Award]
- P. Kudagamage, T. Hayama, “Practical Evaluation of Mental Health Risk Prediction in University Students Using Consumer Smartwatches and Explainable Machine Learning,” in Proc. 20th International Conference on Knowledge, Information and Creativity Support Systems (KICSS 2025) ,pp.158-165 (2025).
- Jyoboji, T. Hayama, “Bottom-Up Handwriting Recognition Using Motion Sensors on a Smartwatch,” in Proc. 20th International Conference on Knowledge, Information and Creativity Support Systems (KICSS 2025) ,pp.64-71 (2025).[Best Poseter Award]